Процессоры
В прошлых главах было рассказано о том, что процессор - это транзисторное исполнение некоторых арифметико-логических схем.

Чем больше в нашем распоряжении транзисторов, тем более сложные и быстродействующие схемы исполнения команд мы можем построить. В пределе можно вообще продумать все возможные команды и их наборы аргументов и заложить логические схемы, которые будут по нужному входному сигналу выдавать заранее запрограммированый ответ.
Т.е. сумма 1 и 2 в первом регистре приведёт к тому, что в первом появится число три. Можно сразу заложить правильный ответ. Но у такого подхода есть два существенных ограничения: первое - это ограниченность в числе транзисторов, как бы ни росло их число на единицу площади, второе - это запредельное число команд, которые могут теоретически быть выполнены процессором. Речь не о типе команд, а наборах одних и тех же команд с разными параметрами. Поэтому инженеры-схемотехники стараются найти оптимальное решение, которое будет работать быстро и при этом решать сразу целый класс задач.
Производство
Современные процессоры исполняются на одном кристалле. Это - единственный способ разместить компактно так много транзисторов. Подробнее о технологии производства процессоров можно прочитать здесь.
С развитием технологи растёт и число транзисторов в одном микропроцессоре. Зависимость числа транзисторов от времени представлена на следующем графике:
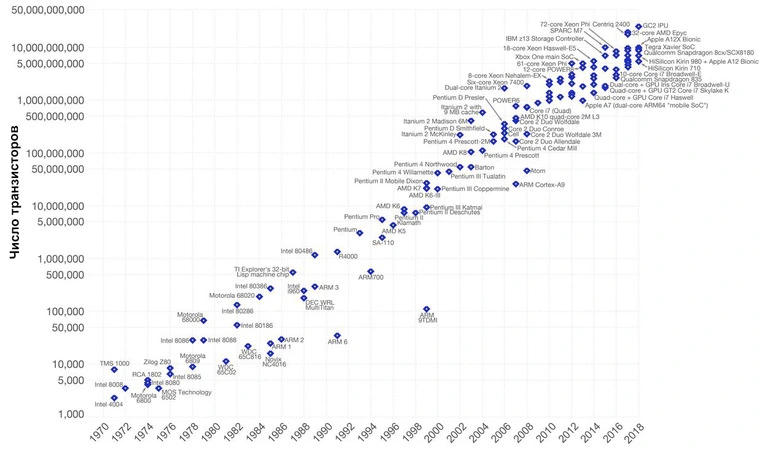
На основе этого графика Гордон Мур сформулировал свой закон - эмпирическое наблюдение, согласно которому (в современной формулировке) количество транзисторов, размещаемых на кристалле интегральной схемы, удваивается каждые 24 месяца.
На втором графике представлена зависимость точности техпроцесса в зависимости от времени.
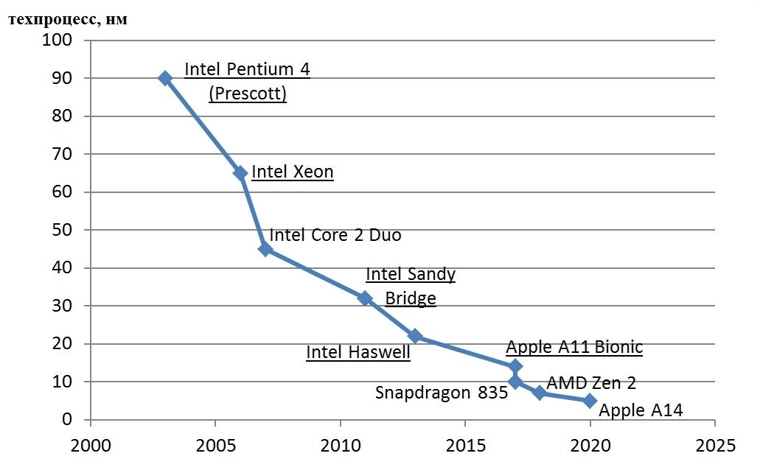
Точность техпроцесса, если упростить, показывает какого минимального размера транзистор мы можем изготовить.
Например, первый процессор компании Intel 4004 производился по технологии с точностью техпроцесса мкм, а сейчас счёт уже идёт на нанометры. Подробнее о развитии техпроцесса можно прочитать здесь.
Несколько лет назад у ведущих по точности техпроцесса компаний произошёл переход с нм на нм. Подробнее можно прочитать здесь.
Недавно компания IBM заявила об освоении техпроцесса точностью в нм, подробнее здесь.
В России производство микропроцессоров довольно развито. В промышленном секторе стандартом является нм. Такие микроконтроллеры используются в довольно широком спектре электронных устройств: от промышленных контроллеров управления приводами до детских игрушек. На сегодняшний день промышленные микропроцессоры завода "Микрон" заняли не только значительную долю рынка России, но и мировых рынков в целом.
По этой же технологии на заводе "Микрон" производится микропроцессор "Эльбрус R1000" у него 4 ядра тактовой частотой до 1000 Мгц. Почему "до", будет объяснено ниже. Всё дело в качественно другой архитектуре.
Эльбрусы разрабатывает компания МЦСТ. Процессоры, производимы на микроне составляют одну из двух линеек, производимых этой компанией.
Вторая линейка - это полноценные процессоры для компьютеров, выполненные хоть и с технологическим отставанием, но это отставание с каждым годом сокращается и сейчас составляет 1-2 года. Производились эти процессоры в Тайване.
Правда, пока что речь идёт о серверных процессорах. Они стоят дороже и нужны государству. К сожалению, серверные процессоры - это обязательный этап в развитии микропроцессоров.
Когда работа над Эльбрусами современного образца только начиналась, российский рынок уже был заполнен компьютерами от Intel. Причём уже на тот момент огромное число программ было написано именно под архитектуру Intel.
Поэтому обычный пользователь был не заинтересован в Эльбрусах, в первую очередь, потому что не было программ, к которым он привык. Оставался только сектор серверов. Обычно на сервере компания или государственная структура использует 2-3 программы, которые можно написать в приемлемые сроки.

Недавно была произведена партия процессоров Эльбрус-16C. Их тактовая частота равна ггц, а точность техпроцесса - нм.
До разрыва производственных цепочек этот процессор отставал всего на пару лет по производительности от Intel. На сегодняшний день производство планируют перенести на завод Микрон. Подробнее здесь.
Уже сейчас ведётся активная разработка нового процессора по технологии нм. Подробнее можно прочитать здесь.
Репортаж о современном производстве микропроцессоров по технологии и нм на российском заводе Микрон:
Разработка
Производство процессора - это всего лишь один из этапов разработки микропроцессоров. Стандартный цикл проектирования процессора - лет, сейчас МЦСТ параллельно разрабатывает 4 разных процессора.
Фабрика получает уже готовый набор файлов, в которых хранятся все параметры, какие именно тразисторы куда должны быть помещены, а, вернее, нанесены.
Разработка микропроцессора выполняется под конкретную фабрику, у каждой свои программы и свои лицензии. Чем более тонкий техпроцесс, тем дороже стоит лицензия.
Сначала разрабатывается логика работы процессора, потом выполняется физическая проработка. После этого изготавливается сам процессор, его корпус и обвязка.
В действительности разработка процессора на этом не заканчивается, необходимо разработать программное обеспечение для работы всего компьютера и, конечно, требуется собрать сам компьютер.
Основная сложность развития микропроцессоров заключается в том, что для каждого повышения точности техпроцесса необходимо прорабатывать множество тонкостей. К сожалению, нельзя просто прибавить транзисторов в те или иные цепи. Вернее, можно проектировать сразу процессор под нм. Но в такой технологии кроется слишком много технических тонкостей, не зная которых можно получить процессор с тактовой частотой 200-300МГц в лучшем случае.
Чтобы процессор мог работать на частотах в несколько гигагерц, требуется решить все технические задачи на текущем уровне и только потом переходить к следующему.
Для тестирования логических схем процессоров используют есть специальные стенды на плисах.

ПЛИС(Программируемая логическая интегральная схема) - это специальная плата, которая создана специально для того, чтобы управлять логикой поведения платы во время программирования, а не изготовления.
Такой подход позволяет создавать типовые ПЛИСы, которые разработчики подстраивают под свою задачу. Ведь арифметико-логические операции - это только часть задач, которые можно решить с помощью логических схем. ПЛИСы широко используются в военной технике, а также в системах обработки сложных сигналов.
Для разработки процессора логику, заложенную в его модели, перекладывают на систему ПЛИСов и тестируют, так ли будет работать эта схема в физическом устройстве, как планировалось, или есть ошибки.
Только после многочисленных испытаний логическая модель передаётся инженерам, чтобы они превратили её в описание физического устройства, а после сформировали пакет документации для производства процессора на фабрике.
Архитектура
Первые архитектурные решения процессоров были просто инструкциями, из каких логических элементов должен состоять процессор. Со временем архитектура разделилась на две части: первая - это описание того, какие команды может обрабатывать процессор, а вторая - это непосредственные логические схемы обработки команд.
Это позволило разделить развитие архитектуры процессоров на соответствующие направления. Управляющие команды любой производитель делает открытыми, иначе программист не сможет ими воспользоваться, а вот то, как именно должен быть процессор, который как можно быстрее обрабатывает эти команды, - является коммерческой тайной и основной ценностью.
Хотя за время развития вычислительной техники было создано довольно много архитектур, на данный момент наиболее распространено три основных группы: CISC, RISC, VLIW.
В каждой группе есть несколько различных семейств. Тем не менее в пределах одной группы использован один и тот же базовый подход, просто с небольшими отличиями.
CISC
Первая группа архитектур - это CISC (complex instruction set computer), переводится, как компьютер со сложным набором инструкций. Первая версия этой группы была предложена в начале шестидесятых и была очень прогрессивной для того времени.
Главное новшество заключалось в том, что пользователь, как и раньше писал программы в машинных кодах, но специальная программа-компилятор изучала порции машинных кодов и отправляла процессору уже свои коды, часто соответствующие многошаговым операциям или нескольким примитивным.
Имея такой новый набор команд, можно строить гораздо более эффективные схемы.

Первые версии архитектуры CISC были очень мощными, однако со временем понимание задач сильно изменилось, к тому же добавилась многоядерность. При этом каждая новая версия могла только расширять предыдущую для обратной совместимости. Если набор команд полностью пересмотреть, тогда программы, написанные под старый набор, не будут запускаться на компьютерах с новыми процессорами.
Проблема многоядерности заключается в том, что архитектура CISC проектировалась под одноядерные процессоры, это означает, что сами команды не предназначены для разделения их между процессорами, а стандарт менять нельзя.
Именно поэтому всё развитие процессоров Intel и AMD направлено на внедрение всяких ухищрений, которые позволят эффективнее разбить однопоточные команды между ядрами. Такие процессоры называют суперскалярными, а сам подход - неявным параллелизмом.
Самое известное ухищрение - это кэш память.
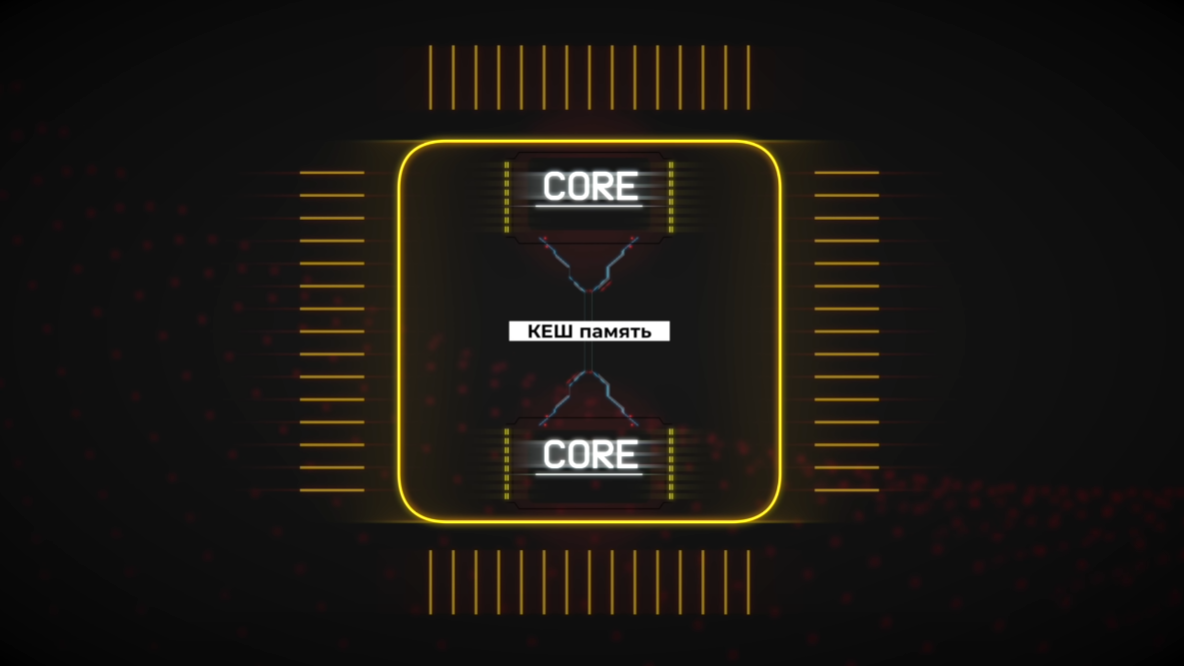
Его идея заключается в том, что он сохраняет последние запрошенные тем или иным ядром данные из оперативной памяти и при следующем обращении по тому же адресу процессор не ждёт, пока ему доставят нужные ему данные, а берёт их из очень быстрого, но маленького по размеру буфера.
Кэш современных процессоров зачастую из –х или -х уровней: L1 (первый уровень), L2 (второй уровень),
L3 (третий уровень)
На следующем рисунке показана структура кэш-памяти четырёхядерного процессора Intel Core i7-3770K. Intel - самый распространённый производитель процессоров с CISC архитектурой.

Кэш первого уровня (L1) – наиболее быстрый уровень кэш-памяти, который работает напрямую с ядром процессора, благодаря этому плотному взаимодействию, данный уровень обладает наименьшим временем доступа и работает на частотах близких процессору. Является буфером между процессором и кэш-памятью второго уровня. У рассматриваемого нами процессора он состоит из четырёх блоков по кб. У каждого ядра свой блок.
Кэш второго уровня (L2) – у этого уровня больше размер, но меньше скорость.
Он служит промежуточным буфером между уровнями L1 и L3.
Этот уровень тоже имеет по одному модулю на ядро, но при этом размер уже кб.
Кэш третьего уровня (L3) – самый медленный, но при этом самый большой уровень.
Тем не менее он гораздо быстрее оперативной памяти, т.к. находится непосредственно внутри корпуса процессора.
Принцип её работы качественно отличается от принципа работы оперативной памяти.
Поэтому кэш-память очень сложно сделать большой по объёму, зато она очень быстрая.
Объём кэша L3 в i7-3770K составляет Мбайт и используется всеми ядрами.
RISC
У процессоров, основанных на CISC архитектуре есть вторая проблема. Она вытекает из первой.
Внутри современных процессоров CISC архитектуры построены очень сложнейшие логические схемы. Чем сложнее схема, тем сложнее её оптимизировать. Плохо оптимизированная логическая схема расходует много энергии, и выделяет её тоже много.
В середине 1970-х разные исследователи выяснили, что большинство комбинаций инструкций и ортогональных методов адресации попросту не используется в реальных задачах. Поэтому требования к набору команд были пересмотрены.
Новую архитектуру назвали RISC (reduced instruction set computer) - переводится, как компьютер с упрощённым набором команд. Проект RISC в Университете Беркли был начат в 1980 году под руководством Дэвида Паттерсона и Карло Секвина.
Также для ускорения обработки команды новой архитектуры определялись равной длины. Это упрощало построение схем и в итоге энергопотребление.

Успехи новой архитектуры были настолько впечатляющими, что в 95-году компания Intel пересмотрела свой подход к проектированию, и в новые процессоры добавили блок преобразования CISC команд в набор нескольких RISC. И уже эти команды обрабатывает то или иное ядро.
По сути, уже почти 30 лет при заявленной CISC архитектуре Intel производит RISC процессоры.
Самый известной архитектурой группы RISC является архитектура ARM (Advanced RISC Machine) - переводится. как усовершенствованная RISC машина.
Эта архитектура повсеместно применяется в процессорах мобильных устройств и просто автоматике.
Недавно процессоры ARM получили новую нишу - тонкие клиенты.
Суть идеи тонкого клиента заключается в том, что вместо покупки 20 компьютеров для офиса, можно купить несколько мощных серверов, а сотрудникам поставить очень слабые компьютеры, мощности которых хватает только для удалённого доступа к серверу. На сервере для каждого клиента запускается сессия и в итоге пока одна часть сотрудников не пользуется мощностями сервера, они в полном распоряжении другой части.
Тонкий клиент можно организовать даже на базе одноплатного компьютера. Подробнее здесь.
У нас в стране производятся копии зарубежных процессоров ARM по лицензии. Эти процессоры называются Байкал.
VLIW
Первые VLIW процессоры были разработаны в конце 1980-х.
VLIW (very long instruction word) - переводится как очень длинная машинная команда.
Эту группу можно считать логическим продолжением группы RISC.
Несмотря на название, основное новшество VLIW заключается не в длине команды. Длина команды - это следствие требований новой теории.
Основная идея рассматриваемой архитектуры заключается в том, что процессор строится не как набор универсальных ядер, а как набор параллельных, узкоспециализированных модулей.

С одной стороны, это качественно расширяет возможности программирования, с другой - осложняет формирование машинных кодов. Ведь для этого нужно держать в голове не просто, какому ядру, какую задачу выполнить, как в RISC, а какому модулю. Модулей гораздо больше, чем ядер, некоторые из них повторяются.
Однако задачка распределения задач между модулями не нужно решать программисту. Он, как и на CISC компьютере должен написать исходный код программы, а довольно непростую задачу распределения команд по модулями выполнит специальная программа компилятор. Это называется явный параллелизм.
Такой подход позволяет очень эффективно распараллеливать задачи. Однако он требует более основательной подготовки.
Процессоры Эльбрус построены на основе их собственно архитектуры E2K, которая как раз принадлежит группе VLIW. В отличие от CISC компилятор Эльбруса анализирует весь код, а не очередную порцию и сразу преобразует его в последовательность VLIW команд. Подробнее здесь/
Заинтересовавшимся советую посмотреть доклад Дмитрия Завалишина "Архитектура процессора Эльбрус 2000". Сделать это можно здесь.